

DTO Layer Refactor for a High-Traffic Marketplace#
TL;DR: I introduced a DTO layer that made data contracts explicit, reduced client payload, and improved performance + reliability on key logged-out experiences.
Context#
In a large marketplace app, pages were shipping oversized API objects to the browser. Frontend teams paid a “data tax” on every request: slower render/hydration, higher memory usage, and increased regression risk when the backend shape changed.
The problem#
- Over-fetching: pages received large objects with many unused fields.
- God objects: components depended on sprawling types, making refactors risky.
- SSR/CSR drift: inconsistent server vs client output increased hydration risk.
- Performance drag: bigger JSON, more parsing, heavier React trees.
What I did#
1) Introduced UI-facing DTOs#
I defined UI-purpose types (e.g. ListingCard, SearchResult, LocationSummary) that include only the fields required for each surface.
- DTOs live at the server boundary (closest to data fetching).
- The client consumes stable, minimal contracts.
- DTOs are versioned or evolved carefully to avoid breaking UI.
2) Standardized mapping + ownership#
I implemented mapping functions and conventions so DTO creation was consistent and reviewable:
- deterministic mapping functions (
toListingCardDTO,toLocationDTO) - unit tests for mapping correctness
- clear ownership: “DTOs are an API for the UI”
3) Measured and proved impact#
To avoid “it feels faster,” I captured:
- payload size deltas (before/after JSON)
- key route timings (TTFB/LCP/INP or closest equivalents)
- SSR consistency checks (to reduce hydration surprises)
Outcomes#
Replace placeholders with your real numbers.
- Payload reduction: ~__% smaller JSON shipped to client
- Performance: improved __ (TTFB / LCP / INP) on key routes
- Reliability: fewer regressions from backend shape changes
- Developer velocity: faster iteration due to smaller, clearer contracts
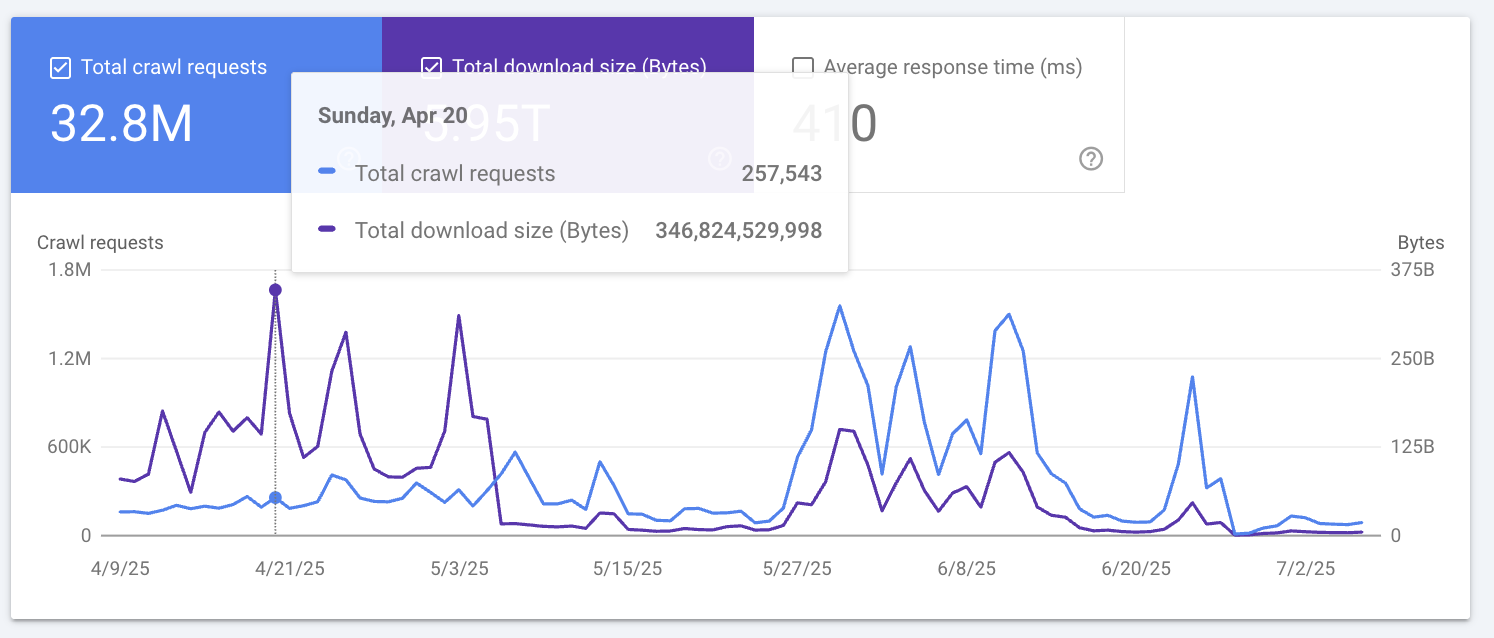
Crawl budget impact (Google Search Console)#
One of the clearest external signals of DTO impact showed up in Google Search Console → Settings → Crawl stats.
By reducing the amount of JSON/data shipped per request (and eliminating unused fields), we lowered the Total download size (Bytes) associated with Googlebot crawling key routes. This is effectively a crawl budget efficiency win: Google can fetch more URLs with less bandwidth, and large-scale crawling becomes cheaper and faster.
Snapshot (example day)#
On Apr 20, 2025, Search Console reported:
- Total crawl requests: 257,543
- Total download size: 346,824,529,998 bytes (~346.8 GB / ~323.0 GiB)
Why this matters#
- Less bandwidth per crawl → more efficient crawling and fewer “heavy page” penalties.
- Faster processing (smaller responses) → improves crawl throughput and reduces strain on edge/origin.
- More stable SSR output + smaller payloads → reduces risk of render variance for crawlers.
What changed technically#
- Introduced UI-facing DTOs to prevent over-fetching.
- Centralized mapping at the server boundary so only necessary fields are serialized.
- Added safeguards (types + tests) to avoid payload creep over time.
My role#
Staff-level ownership across design + rollout:
- architecture decision + RFC
- implementation guidance and PR reviews
- migration plan (incremental adoption)
- alignment with SEO, analytics, product, and design partners
Tech stack#
- Next.js (App Router), React, TypeScript
- Node.js data fetching layer
- Jest for mapping tests
- Observability: Datadog RUM (optional), BigQuery/GA4/Snowplow (optional)
Proof / artifacts#
Add links as you publish them.
- Architecture diagram (DTO boundary + data flow)
- Before/after payload comparison screenshot
- Performance dashboard screenshot
- Example DTO type + mapper snippet
Next#
If you’re building a large SSR app, DTOs are a performance and reliability primitive, not just “clean code.”